Scikit |
您所在的位置:网站首页 › pca降维 sklearn › Scikit |
Scikit
|
主要成分分析(PCA)
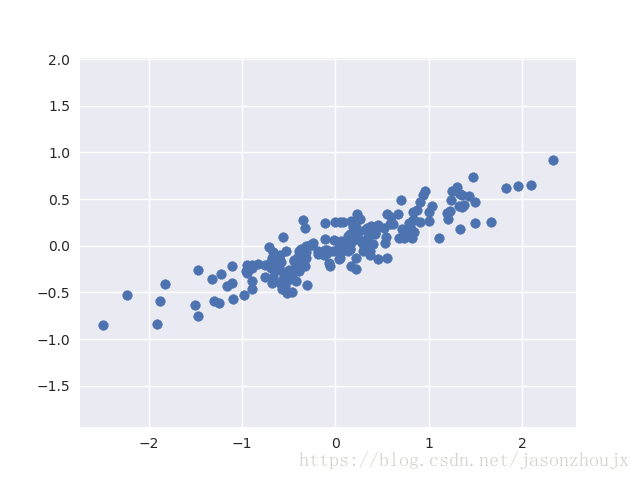
主要成分分析(PCA)可能是应用最广泛的无监督算法之一。虽然PCA是一种非常基础的降维算法,但它仍然是非常有用的工具,尤其适用于数据可视化、噪音过滤、特征抽取和特征工程等领域。由于PCA用途广泛、可解释性强,所以可以有效应用于大量情景和科学中。对于任意高维的数据集,可以从PCA开始,可视化点间的关系、理解数据中的主要变量。PCA并不是一个对每个高维数据集都有效的算法,但是它提供了一条直接且有效的路径,来获得对高维数据的洞察。 用PCA降维用PCA降维意味着去除一个或多个最小主成份,从而得到一个更低维度且保留最大数据方差的数据投影。 %matplotlib inline import numpy as np import matplotlib.pyplot as plt import seaborn as sns;sns.set() #产生实验数据 rng = np.random.RandomState(1) x = np.dot(rng.rand(2, 2), rng.randn(2, 200)).T plt.scatter(x[:, 0], x[:, 1]) plt.axis('equal');浅色的点是原始数据,深色的数据是投影的版本。我们可以看到PCA降维的含义:沿着最不重要的主轴的信息都被去除了,仅留下了含有最高方差值的数据成分。被去除的那一小部分方差值基本可以看成是数据降维后损失的“信息”量。 用PCA做数据可视化 #将手写数据从8x8=64维空间降维到二维空间,进行可视化 from sklearn.datasets import load_digits digits = load_digits() pca = PCA(2) projected = pca.fit_transform(digits.data) #画出每个点的前两个主成份 plt.scatter(projected[:, 0], projected[:, 1], c=digits.target, edgecolor='none', alpha=0.5, cmap=plt.cm.get_cmap('Spectral', 10)) plt.xlabel('component 1') plt.ylabel('component 2') plt.colorbar();我们可以通过累计方差贡献值和希望保留的原始数据的信息量来确定需要保留的主成份数量。 pca = PCA().fit(digits.data) plt.plot(np.cumsum(pca.explained_variance_ratio_)) plt.xlabel('number of components') plt.ylabel('cumulative explained variance');由图可知,二维的投影会损失很多信息,我们需要大约20个成分来保持90%的方差。 用PCA做噪音过滤PCA也可以被用作噪音数据的过滤方法——任何成分的方差都远大于噪音的方差,所以相比于噪音,成分应该相对不受影响。因此,如果你仅用主成份的最大子集重构该数据,那么应该可以实现选择性保留信号并且丢弃噪音。 #先画一个没有噪音的手写数字的图像 def plot_digits(data): fig, axes = plt.subplots(4, 10, figsize=(10, 4), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i, ax in enumerate(axes.flat): ax.imshow(data[i].reshape(8, 8), cmap='binary', interpolation='nearest', clim=(0, 16)) plot_digits(digits.data)PCA投影结果可以作为特征选择器,然后将选择的特征进行机器学习。下面来看人脸识别中对人脸数据进行降维后的主要成分的可视化。 from sklearn.datasets import fetch_lfw_people faces = fetch_lfw_people(min_faces_per_person=60) from sklearn.decomposition import RandomizedPCA pca=RandomizedPCA(150) pca.fit(faces.data) #可视化特征脸 fig, axes = plt.subplots(3, 8, figsize=(9, 4), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0, wspace=0.1)) for i, ax in enumerate(axes.flat): ax.imshow(pca.components_[i].reshape(62, 47), cmap='bone')可以看出从3000多个原始特征中选出的150个主成分已经能够还原大部分的信息。 |








【本文地址】